> ## Documentation Index
> Fetch the complete documentation index at: https://docs.matterai.so/llms.txt
> Use this file to discover all available pages before exploring further.
# Models Overview
> Overview of Axon AI Models - secure, production-ready AI models for general-purpose tasks, coding and deep-research.
 **Axon offers secure, production-ready AI models for both code generation and general-purpose tasks, leveraging State-of-the-Art Deep Reasoning powered by Interleaved Reasoning [https://arxiv.org/abs/2505.19640](https://arxiv.org/abs/2505.19640) and State Machines**
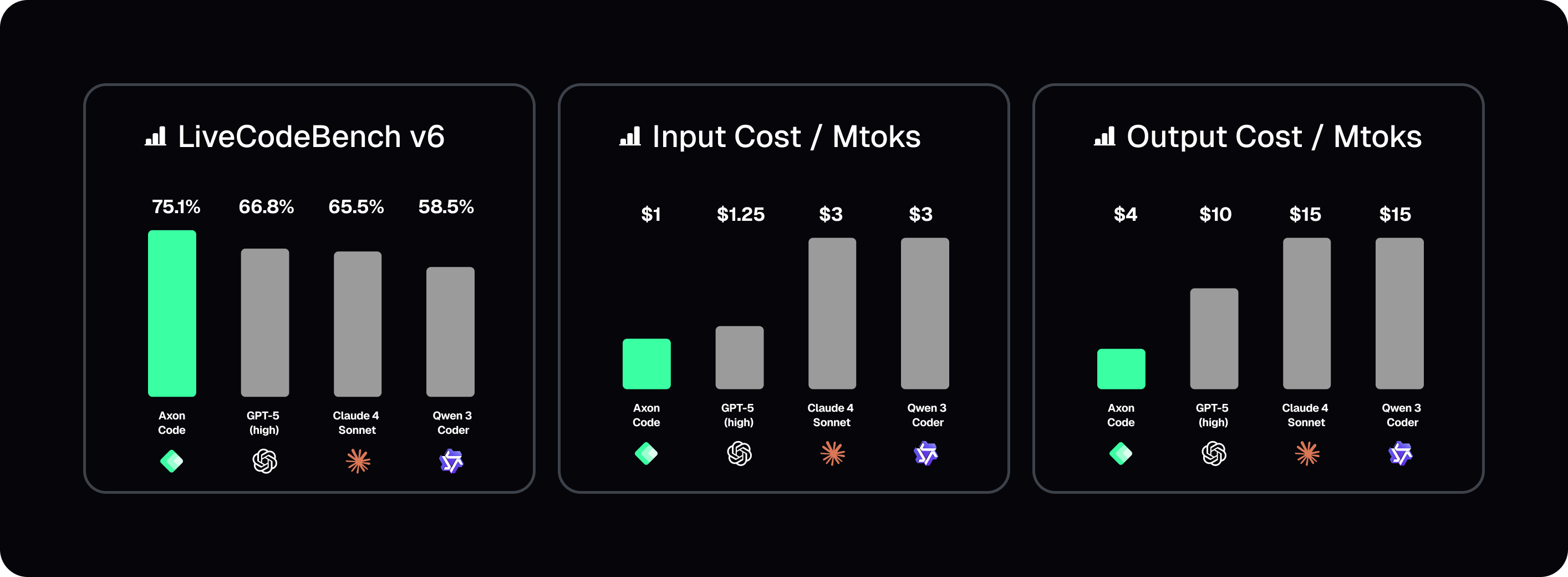
## Benchmarks
**Axon offers secure, production-ready AI models for both code generation and general-purpose tasks, leveraging State-of-the-Art Deep Reasoning powered by Interleaved Reasoning [https://arxiv.org/abs/2505.19640](https://arxiv.org/abs/2505.19640) and State Machines**
## Benchmarks
 ## Architecture
Axon Models are based on open source models from Kimi and Deepseek, fine tuned
on our proprietary dataset and upgraded with deep reasoning and state machine
capabilities.
### Mixture of Experts (MoE) architecture
MoE is a technique that allows the model to dynamically select the expert model to use for a given input.
This architecture enables engineering teams to build more scalable and efficient systems by routing tasks to specialized experts, reducing computational overhead while maintaining high performance across diverse workloads.
## What makes Axon different?
* **Deep Reasoning**: Our SOTA Deep Reasoner generates a detailed reasoning process for your requests, detects what needs to be done and how to do it, ensuring all the context is considered and the best possible solution is provided.
* **State Machines**: Our SOTA State Machine uses temporal memories to remember your continued flow of usage on what has accomplished and what needs to be completed next.
## Deep Reasoner
Our State-of-the-Art Deep Reasoner generates a detailed reasoning process for your requests, detects what needs to be done and how to do it, ensuring all the context is considered and the best possible solution is provided.
* **Multi-sources causal graph traversal** for inferencing across heterogeneous data sources, enabling root-cause analysis and counterfactual reasoning.
* **Dynamic symbolic grounding** via contextual ontologies to map abstract concepts into actionable knowledge representations in real time.
* **Probabilistic logic synthesis** with uncertainty quantification to evaluate solution optimality under incomplete or ambiguous input conditions.
* **Hierarchical attention over structured memory** to maintain long-range dependencies during complex, multi-step problem decomposition.
* **Meta-cognitive feedback loops** that refine internal heuristics based on outcome validation, improving future reasoning trajectories.
* **Real-time web search integration** with federated query optimization across multiple search providers for comprehensive knowledge retrieval.
* **Adaptive web content parsing** using semantic-aware scrapers that extract structured data from dynamic web sources while respecting rate limits and ToS.
## Architecture
Axon Models are based on open source models from Kimi and Deepseek, fine tuned
on our proprietary dataset and upgraded with deep reasoning and state machine
capabilities.
### Mixture of Experts (MoE) architecture
MoE is a technique that allows the model to dynamically select the expert model to use for a given input.
This architecture enables engineering teams to build more scalable and efficient systems by routing tasks to specialized experts, reducing computational overhead while maintaining high performance across diverse workloads.
## What makes Axon different?
* **Deep Reasoning**: Our SOTA Deep Reasoner generates a detailed reasoning process for your requests, detects what needs to be done and how to do it, ensuring all the context is considered and the best possible solution is provided.
* **State Machines**: Our SOTA State Machine uses temporal memories to remember your continued flow of usage on what has accomplished and what needs to be completed next.
## Deep Reasoner
Our State-of-the-Art Deep Reasoner generates a detailed reasoning process for your requests, detects what needs to be done and how to do it, ensuring all the context is considered and the best possible solution is provided.
* **Multi-sources causal graph traversal** for inferencing across heterogeneous data sources, enabling root-cause analysis and counterfactual reasoning.
* **Dynamic symbolic grounding** via contextual ontologies to map abstract concepts into actionable knowledge representations in real time.
* **Probabilistic logic synthesis** with uncertainty quantification to evaluate solution optimality under incomplete or ambiguous input conditions.
* **Hierarchical attention over structured memory** to maintain long-range dependencies during complex, multi-step problem decomposition.
* **Meta-cognitive feedback loops** that refine internal heuristics based on outcome validation, improving future reasoning trajectories.
* **Real-time web search integration** with federated query optimization across multiple search providers for comprehensive knowledge retrieval.
* **Adaptive web content parsing** using semantic-aware scrapers that extract structured data from dynamic web sources while respecting rate limits and ToS.
 ## State Machine
Our State-of-the-Art State Machine Engine uses temporal memories to remember your continued flow of usage on what has accomplished and what needs to be completed next.
* **Hierarchical semi-Markov decision processes** (HSMDPs) for modeling variable-duration states and adaptive task sequencing.
* **Distributed state persistence with vector-clock reconciliation** to ensure consistency across asynchronous, concurrent user sessions.
* **Reinforcement learning-driven transition policies** that optimize long-term user goal completion over immediate action rewards.
* **Temporal difference learning over latent state embeddings** to predict and pre-fetch likely next states for zero-latency transitions.
* **Context-sensitive state compression** using learned subroutines to reduce combinatorial state explosion while preserving semantic fidelity.
## State Machine
Our State-of-the-Art State Machine Engine uses temporal memories to remember your continued flow of usage on what has accomplished and what needs to be completed next.
* **Hierarchical semi-Markov decision processes** (HSMDPs) for modeling variable-duration states and adaptive task sequencing.
* **Distributed state persistence with vector-clock reconciliation** to ensure consistency across asynchronous, concurrent user sessions.
* **Reinforcement learning-driven transition policies** that optimize long-term user goal completion over immediate action rewards.
* **Temporal difference learning over latent state embeddings** to predict and pre-fetch likely next states for zero-latency transitions.
* **Context-sensitive state compression** using learned subroutines to reduce combinatorial state explosion while preserving semantic fidelity.
 ## Model Family
General Purpose Model for high-effort day to day tasks
General Purpose Model for low-effort day to day tasks
Code Generation Model for high-effort coding tasks
## Getting Started
### Get API Key
Generate a new API key
### API & SDK Integration
```bash cURL theme={null}
curl --request POST \
--url https://api.matterai.so/v1/chat/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer MATTER_API_KEY' \
--data '{
"model": "{{MODEL_ID}}",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is Rust?"
}
],
"stream": false,
"max_tokens": 1000,
"reasoning": {
"effort": "high",
"summary": "none"
},
"response_format": {
"type": "text"
},
"temperature": 0,
"top_p": 1
}'
```
```javascript OpenAI NodeJS SDK theme={null}
import OpenAI from "openai";
const openai = new OpenAI({
apiKey: "MATTER_API_KEY",
baseURL: "https://api.matterai.so/v1",
});
async function main() {
const response = await openai.chat.completions.create({
model: "{{MODEL_ID}}",
messages: [
{
role: "system",
content: "You are a helpful assistant.",
},
{
role: "user",
content: "What is Rust?",
},
],
stream: false,
max_tokens: 1000,
reasoning: {
effort: "high",
summary: "none",
},
response_format: {
type: "text",
},
temperature: 0,
top_p: 1,
});
console.log(response.choices[0].message.content);
}
main();
```
```python OpenAI Python SDK theme={null}
from openai import OpenAI
client = OpenAI(
api_key='MATTER_API_KEY',
base_url='https://api.matterai.so/v1'
)
response = client.chat.completions.create(
model='{{MODEL_ID}}',
messages=[
{
'role': 'system',
'content': 'You are a helpful assistant.'
},
{
'role': 'user',
'content': 'What is Rust?'
}
],
stream=False,
max_tokens=1000,
reasoning={
'effort': 'high',
'summary': 'none'
},
response_format={
'type': 'text'
},
temperature=0,
top_p=1
)
print(response.choices[0].message.content)
```
# Data Privacy
MatterAI never trains on your codebase, all data is temporary and deleted
automatically.
## Model Family
General Purpose Model for high-effort day to day tasks
General Purpose Model for low-effort day to day tasks
Code Generation Model for high-effort coding tasks
## Getting Started
### Get API Key
Generate a new API key
### API & SDK Integration
```bash cURL theme={null}
curl --request POST \
--url https://api.matterai.so/v1/chat/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer MATTER_API_KEY' \
--data '{
"model": "{{MODEL_ID}}",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is Rust?"
}
],
"stream": false,
"max_tokens": 1000,
"reasoning": {
"effort": "high",
"summary": "none"
},
"response_format": {
"type": "text"
},
"temperature": 0,
"top_p": 1
}'
```
```javascript OpenAI NodeJS SDK theme={null}
import OpenAI from "openai";
const openai = new OpenAI({
apiKey: "MATTER_API_KEY",
baseURL: "https://api.matterai.so/v1",
});
async function main() {
const response = await openai.chat.completions.create({
model: "{{MODEL_ID}}",
messages: [
{
role: "system",
content: "You are a helpful assistant.",
},
{
role: "user",
content: "What is Rust?",
},
],
stream: false,
max_tokens: 1000,
reasoning: {
effort: "high",
summary: "none",
},
response_format: {
type: "text",
},
temperature: 0,
top_p: 1,
});
console.log(response.choices[0].message.content);
}
main();
```
```python OpenAI Python SDK theme={null}
from openai import OpenAI
client = OpenAI(
api_key='MATTER_API_KEY',
base_url='https://api.matterai.so/v1'
)
response = client.chat.completions.create(
model='{{MODEL_ID}}',
messages=[
{
'role': 'system',
'content': 'You are a helpful assistant.'
},
{
'role': 'user',
'content': 'What is Rust?'
}
],
stream=False,
max_tokens=1000,
reasoning={
'effort': 'high',
'summary': 'none'
},
response_format={
'type': 'text'
},
temperature=0,
top_p=1
)
print(response.choices[0].message.content)
```
# Data Privacy
MatterAI never trains on your codebase, all data is temporary and deleted
automatically.